本文共 10951 字,大约阅读时间需要 36 分钟。
1. 背景
APIServer 已有一个简单的机制 (MaxInFlightLimit) 来保护自己不受 CPU 和内存过载的影响。通过 --max-requests-inflight 和 --max-mutating-requests-inflight 限制待处理的请求数量。
这种方式存在一些明显的缺陷:
- 除了区分 mutating 和 readonly 之外,请求之间没有其他区别,管理粒度比较粗
- 一个大流量的请求子集可能会挤掉其他的请求,如果一些非常重要的请求 (sysytem controllers, leader elections) 被挤掉,后果比较严重。
2. APF 的整体设计
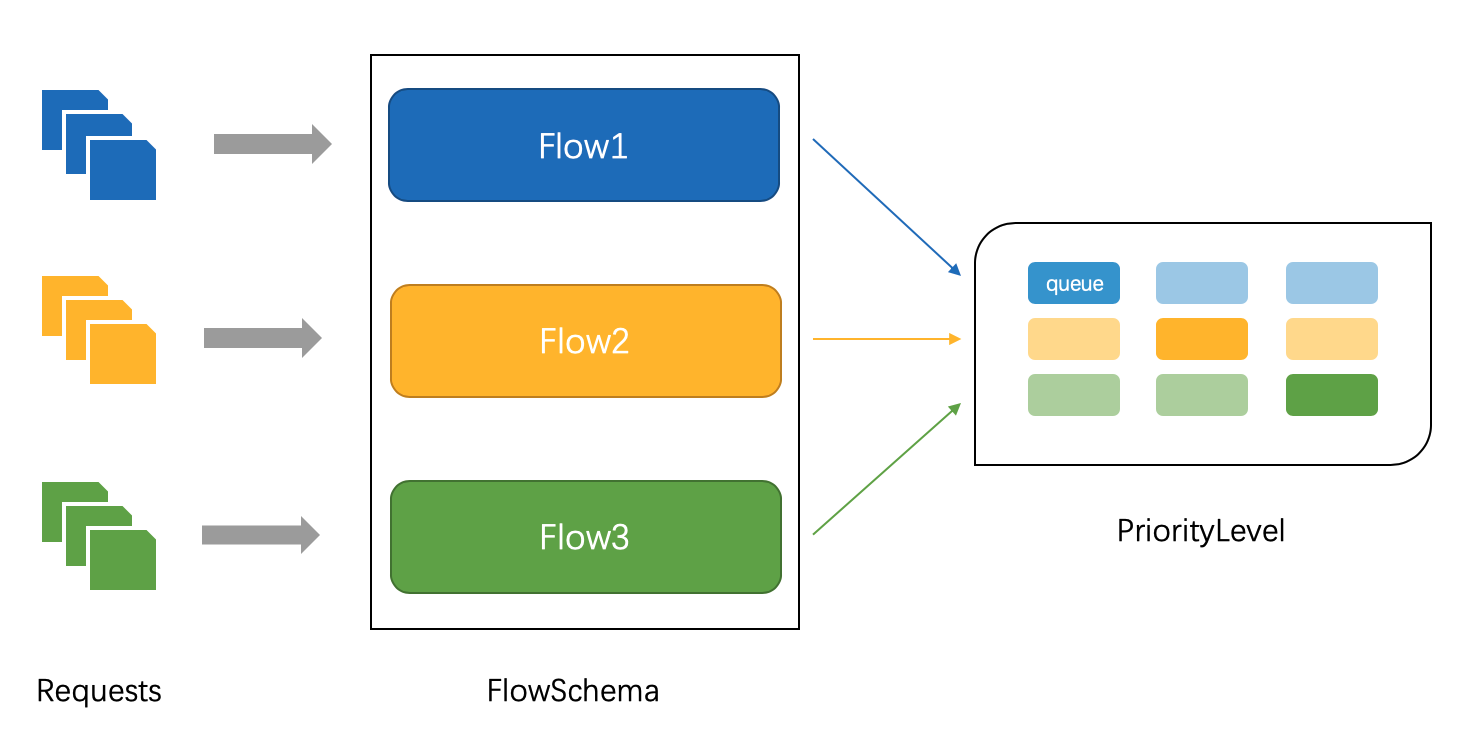
API Priority and Fairness (APF) 是 K8s v1.18 的一个 alpha 特性。APF 这种替代方案可以规避 MaxInFlightLimit 方案存在的问题。下面介绍 APF 的整体设计,从中可以看出 APF 到底是如何规避这些问题的。
-
APF 的实现依赖两个非常重要的资源 FlowSchema, PriorityLevelConfiguration
-
APF 对请求进行更细粒度的分类,每一个请求分类对应一个 FlowSchema (FS).
-
FS 内的请求又会根据 distinguisher 进一步划分为不同的 Flow.
-
FS 会设置一个优先级 (Priority Level, PL),不同优先级的并发资源是隔离的。所以不同优先级的资源不会相互排挤。特定优先级的请求可以被高优处理。
-
一个 PL 可以对应多个 FS,PL 中维护了一个 QueueSet,用于缓存不能及时处理的请求,请求不会因为超出 PL 的并发限制而被丢弃。
-
FS 中的每个 Flow 通过 shuffle sharding 算法从 QueueSet 选取特定的 queues 缓存请求。
-
每次从 QueueSet 中取请求执行时,会先应用 fair queuing 算法从 QueueSet 中选中一个 queue,然后从这个 queue 中取出 oldest 请求执行。所以即使是同一个 PL 内的请求,也不会出现一个 Flow 内的请求一直占用资源的不公平现象。
2.1 FlowSchema
1、如何对请求进行分类?
用户可以通过创建 FlowSchema 资源对象自定义分类方式。
FS 代表一个请求分类,包含多条匹配规则,如果某个请求能匹配其中任意一条规则就认为这个请求属于这个 FS (只匹配第一个匹配的 FS)。
// FS 规则// FlowSchemaSpec describes how the FlowSchema's specification looks like.type FlowSchemaSpec struct { ... Rules []PolicyRulesWithSubjects `json:"rules,omitempty" protobuf:"bytes,4,rep,name=rules"`} 请求与 FS 规则匹配:同时满足以下条件,就认为请求与该 FS 规则匹配
- 匹配请求主体 subject
- 对资源的请求,匹配 ResourceRules 中任意一条规则
- 对非资源的请求, 匹配 NonResourceRules 中任意一条规则
type PolicyRulesWithSubjects struct { Subjects []Subject ResourceRules []ResourcePolicyRule NonResourceRules []NonResourcePolicyRule}type Subject struct { Kind SubjectKind `json:"kind" protobuf:"bytes,1,opt,name=kind"` User *UserSubject `json:"user,omitempty" protobuf:"bytes,2,opt,name=user"` Group *GroupSubject `json:"group,omitempty" protobuf:"bytes,3,opt,name=group"` ServiceAccount *ServiceAccountSubject `json:"serviceAccount,omitempty" protobuf:"bytes,4,opt,name=serviceAccount"`}type ResourcePolicyRule struct { Verbs []string `json:"verbs" protobuf:"bytes,1,rep,name=verbs"` APIGroups []string `json:"apiGroups" protobuf:"bytes,2,rep,name=apiGroups"` Resources []string `json:"resources" protobuf:"bytes,3,rep,name=resources"` ClusterScope bool `json:"clusterScope,omitempty" protobuf:"varint,4,opt,name=clusterScope"` Namespaces []string `json:"namespaces" protobuf:"bytes,5,rep,name=namespaces"`}type NonResourcePolicyRule struct { Verbs []string `json:"verbs" protobuf:"bytes,1,rep,name=verbs"` NonResourceURLs []string `json:"nonResourceURLs" protobuf:"bytes,6,rep,name=nonResourceURLs"`} 总之,通过 FS,可以根据请求的主体 (User, Group, ServiceAccout)、动作 (Get, List, Create, Delete …)、资源类型 (pod, deployment …)、namespace、url 对请求进行分类。
2、FS 内的请求如何进一步划分 Flow ?
有两种方式对请求进行 Flow 划分:
- distinguisher = ByUser, 根据请求的 User 划分不同 Flow;可以让来自不同用户的请求平等使用 PL 内的资源。
- distinguisher = ByNamespace, 根据请求的 namespace 划分不同的 Flow;可以让来自不同 namespace 的请求平等使用 PL 内的资源。
- distinguisher = nil,表示不划分
distinguisher 的取值由请求所属的 FS 决定:
type FlowSchemaSpec struct { ... DistinguisherMethod *FlowDistinguisherMethod `json:"distinguisherMethod,omitempty" protobuf:"bytes,3,opt,name=distinguisherMethod"` ...}type FlowDistinguisherMethod struct { Type FlowDistinguisherMethodType `json:"type" protobuf:"bytes,1,opt,name=type"`}type FlowDistinguisherMethodType stringconst ( FlowDistinguisherMethodByUserType FlowDistinguisherMethodType = "ByUser" FlowDistinguisherMethodByNamespaceType FlowDistinguisherMethodType = "ByNamespace") 3、如何给请求分配优先级?
FS 通过 FlowSchema.Spec.PriorityLevelConfiguration.Name 指定 PL,从属于这个 FS 的所有请求都划分到这个优先级中。
2.2 Priority Level
用户可以通过创建 PriorityLevelConfiguration 资源对象自定义 PL。
如果 API sever 启动了 APF,它的总并发数为 --max-requests-inflight 和 --max-mutating-requests-inflight 两个配置值之和。这些并发数被分配给各个 PL,分配方式是根据 PriorityLevelConfiguration.Spec.Limited.AssuredConcurrencyShares 的数值按比例分配。PL 的 AssuredConcurrencyShare 越大,分配到的并发份额越大。
每个 PL 都对应维护了一个 QueueSet,其中包含多个 queue ,当 PL 达到并发限制时,收到的请求会被缓存在 QueueSet 中,不会丢弃,除非 queue 也达到了容量限制。
QueueSet 中 queue 数量由PriorityLevelConfiguration.Spec.Limited.LimitResponse.Queuing.Queues 指定;每个 queue 的长度由 PriorityLevelConfiguration.Spec.Limited.LimitResponse.Queuing.QueueLengthLimit 指定。
5 个推荐的 PL
| PL | request |
|---|---|
| system | 来自 system:nodes group 的请求 |
| leader-election | 内建 controller 的 leader election 请求 |
| workload-high | 内建 controller 的其他请求 |
| workload-low | 来自其他 service account 的请求 |
| global-default | 所有其他的请求 |
2.3 两对内建的 PL 和 FS
Exempt PL (PriorityLevelConfigurations.Spec.Type = exempt):这个 PL 内的请求完全不受限制,总是被立即执行。
Exempt FS:将来自 system:master group 的所有请求划分到 Exempt PL。用户可以自定义 FS 将一些特殊的请求划分到 Exempt PL 中。
catch-all PL:只有一个并发配额,没有 queue。一般会返回 HTTP 429 错误。
catch-all FS:说有未能匹配其他 FS 的请求,最终会被这个 FS 匹配上。保证所有的请求都有一个分类。
由于 request 只匹配第一个符合条件的 FS,所以 APF 会对 FS 进行排序,将 Exempt FS 排第一位,catch-all FS 排最后一位。
// sort into the order to be used for matchingsort.Sort(fsSeq)// Supply missing mandatory FlowSchemas, in correct positionif !haveExemptFS { // 放在第一位 fsSeq = append(apihelpers.FlowSchemaSequence{ fcboot.MandatoryFlowSchemaExempt}, fsSeq...)}if !haveCatchAllFS { // 放在最后一位 fsSeq = append(fsSeq, fcboot.MandatoryFlowSchemaCatchAll)} 3. 请求流程
1、分配 queue
API Server 接收到请求后,先按照前面提到的方式,找到与之匹配的 FS,实现分类,并根据 FS 确定请求的所属的Flow 和 PL。
APF 利用 FS 的 name 和请求的 userName 或 namespace 计算一个 hashFlowID 标识 Flow。
var hashValue uint64if numQueues > 1 { // 1. DistinguisherMethod = ByUser, flowDistinguisher = rd.User.Name // 2. DistinguisherMethod = ByNamespace, flowDistinguisher = rd.RequestInfo.Namespace // 3. DistinguisherMethod = nil, flowDistinguisher = "" flowDistinguisher := computeFlowDistinguisher(rd, fs.Spec.DistinguisherMethod) hashValue = hashFlowID(fs.Name, flowDistinguisher)} 然后利用这个 hashFlowID 通过 Shuttle Sharding 算法,从请求所属的 PL 的 QueueSet 中选取指定数目的 queues (PriorityLevelConfiguration.Spec.Limited.LimitResponse.Queuing.HandSize):
func (d *Dealer) Deal(hashValue uint64, pick func(int)) { // 15 is the largest possible value of handSize var remainders [15]int for i := 0; i < d.handSize; i++ { hashValueNext := hashValue / uint64(d.deckSize-i) remainders[i] = int(hashValue - uint64(d.deckSize-i)*hashValueNext) hashValue = hashValueNext } // 防止重复:正反馈机制,大者更大 for i := 0; i < d.handSize; i++ { card := remainders[i] for j := i; j > 0; j-- { if card >= remainders[j-1] { // 不会出现 card > deckSize // 因为 hashValue % uint64(d.deckSize-i) <= d.deckSize-i-1,而第 i 个 card 最多自增 i 次 card++ } } pick(card) }} 然后从这些候选的 queues 中,选择其中 length 最小 queue. 并移出 queue 中超时的请求。
判断是否入队这个请求:如果队列已满且 PL 中正在执行的请求数达到 PL 的并发限制,就会拒绝这个请求,否则入队这个请求。
此处保证了不同 Flow 的请求不会挤掉其他 Flow 的请求。Flow 是按照用户或 namespace 划分的,它的实际意义就是来自不同用户或 namespace 的请求不会挤掉同优先级的其他用户或 namespace 的请求。
2、分发请求
为了保证同一个 PL 中缓存的不同 Flow 的请求被处理机会平等,每次分发请求时,都会先应用 fair queuing 算法从 PL 的 QueueSet 中选中一个 queue:
// selectQueueLocked examines the queues in round robin order and// returns the first one of those for which the virtual finish time of// the oldest waiting request is minimal.func (qs *queueSet) selectQueueLocked() *queue { minVirtualFinish := math.Inf(1) var minQueue *queue var minIndex int nq := len(qs.queues) for range qs.queues { qs.robinIndex = (qs.robinIndex + 1) % nq queue := qs.queues[qs.robinIndex] if len(queue.requests) != 0 { currentVirtualFinish := queue.GetVirtualFinish(0, qs.estimatedServiceTime) if currentVirtualFinish < minVirtualFinish { minVirtualFinish = currentVirtualFinish minQueue = queue minIndex = qs.robinIndex } } } // we set the round robin indexing to start at the chose queue // for the next round. This way the non-selected queues // win in the case that the virtual finish times are the same qs.robinIndex = minIndex return minQueue} fiar queuing 选 queue 的基本思路是:
1)每一个 queue 都维护了一个 virtualStart: oldest 请求的虚拟开始执行时间
type queue struct { requests []*request // 如果队列中没有 request 且没有 request 在执行 (requestsExecuting = 0), virtualStart = queueSet.virtualTime // 每分发一个 request, virtualStart = virtualStart + queueSet.estimatedServiceTime // 每执行完一个 request, virtualStart = virtualStart - queueSet.estimatedServiceTime + actualServiceTime,用真实的执行时间,校准 virtualStart // 计算第 J 个 request 的 virtualFinishTime = virtualStart + (J+1) * serviceTime virtualStart float64 requestsExecuting int index int} 比较关键的一点是:virtualStart 如何进行初始化?
virtualStart 初始化是直接设置为 QueueSet 中维护的 virtualTime。而 QueueSet.virtualTime 是在这个 PL 初始化的时候赋值为 0。此后,如果 QueueSet 中的 queue 如有任何状态变化,都要执行更新,根据自身两次变更历经的 realTime 按比例增加:
func (qs *queueSet) syncTimeLocked() {
realNow := qs.clock.Now() timeSinceLast := realNow.Sub(qs.lastRealTime).Seconds() qs.lastRealTime = realNow qs.virtualTime += timeSinceLast * qs.getVirtualTimeRatioLocked() }其中,这个比例计算方式为:min(QueueSet 中正字执行的请求数, PL 的并发配额) / QueueSet 中活跃的 queue 数目。
virtualTime 实际对应于 bit-by-bit round-robin 算法中的 R(t),当前时间 round-robin 轮数。具体可以参考文后第4个链接。
- 选 queue 时,会估计每个 queue 中 oldest 请求的虚拟执行完毕时间,选择这个虚拟执行完毕时间最小的 queue
选中 queue 之后,从 queue 中取出 oldest 请求,设置执行标记。
重复执行以上选 queue 给 oldest 请求设置执行标志,直到 PL 所有的 Queue 中都没有缓存的请求或达到 PL 的并发限制。
注:此处是尽可能多的分发 PL 中缓存的请求,有可能当前新加入的请求不会被分发。
3、请求阻塞监听执行
完成以上操作之后,该请求会进入阻塞监听状态,直到被分发。
func (req *request) wait() (bool, bool) { qs := req.qs qs.lock.Lock() defer qs.lock.Unlock() ... // 里面包含一个条件锁,阻塞,等待唤醒 decisionAny := req.decision.GetLocked() ... decision, isDecision := decisionAny.(requestDecision) if !isDecision { panic(fmt.Sprintf("QS(%s): Impossible decision %#+v (of type %T) for request %#+v %#+v", qs.qCfg.Name, decisionAny, decisionAny, req.descr1, req.descr2)) } switch decision { case decisionReject: klog.V(5).Infof("QS(%s): request %#+v %#+v timed out after being enqueued\n", qs.qCfg.Name, req.descr1, req.descr2) metrics.AddReject(qs.qCfg.Name, req.fsName, "time-out") return false, qs.isIdleLocked() case decisionCancel: // TODO(aaron-prindle) add metrics for this case klog.V(5).Infof("QS(%s): Ejecting request %#+v %#+v from its queue", qs.qCfg.Name, req.descr1, req.descr2) return false, qs.isIdleLocked() case decisionExecute: klog.V(5).Infof("QS(%s): Dispatching request %#+v %#+v from its queue", qs.qCfg.Name, req.descr1, req.descr2) return true, false default: // This can not happen, all possible values are handled above panic(decision) }} 4、 请求执行
如果这个请求被唤醒,并收到了 decisionExecute 标记,便会开始执行。
func (req *request) Finish(execFn func()) bool { exec, idle := req.wait() if !exec { return idle } // 请求执行 execFn() // 分发请求 return req.qs.finishRequestAndDispatchAsMuchAsPossible(req)} 执行完毕后,便会释放一个并发资源,于是会触发新一轮的请求分发。
4. 如何启用 APF?
kube-apiserver \--feature-gates=APIPriorityAndFairness=true \--runtime-config=flowcontrol.apiserver.k8s.io/v1alpha1=true \ # …and other flags as usual
“–enable-priority-and-fairness=false” 选项会禁用 APF,即使以上选项已启用。
参考
https://kubernetes.io/blog/2020/04/06/kubernetes-1-18-feature-api-priority-and-fairness-alpha/
https://kubernetes.io/docs/concepts/cluster-administration/flow-control/
https://en.wikipedia.org/wiki/Fair_queuing
http://www.iitg.ac.in/nselvaraju/ma402_2007/Assignments/04010605_tp.pdf
转载地址:http://fqrii.baihongyu.com/